
Privacy Icons – Datenschutz braucht ein besseres Storytelling
03.06.2024Wohl kaum jemand liest gerne Datenschutzerklärungen, aber viele von uns nutzen Apps für alles Mögliche – und dabei werden unsere Daten ständig von anderen verarbeitet, ohne dass wir wissen, was genau mit ihnen passiert.
Die meisten von uns, ob nun aus der „Generation Daueronline“ oder Digital-Detox-Affine, finden das Thema Datenschutz ziemlich langweilig und fast niemand liest Datenschutzerklärungen. Doch in einer Welt, in der wir tagtäglich auf „Akzeptieren“ klicken müssen, um Zugang zu Apps zu erhalten – ob nun zum Essenbestellen, zum Geldüberweisen oder zum Videospielen –werden unsere Daten ständig und überall von Fremden verarbeitet, ohne dass wir wirklich verstehen, was damit passieren könnte.
Die EU hat bereits 2016 die Datenschutzgrundverordnung (DSGVO) beschlossen. Sie schreibt vor, unter welchen Umständen unsere personenbezogenen Daten verarbeitet werden dürfen und dass wir darüber informiert werden müssen. Die Informationen sind also da, aber es informiert sich niemand. Wie schaffen wir es also, dem Datenschutz ein besseres Storytelling zu verpassen? Im Projekt „Privacy Icons“ haben Forscher:innen am Weizenbaum-Institut Lukas Seiling, Rita Gsenger, Filmona Mulugeta, Marte Henningsen, Lena Mischau, Marie Schirmbeck und weitere seit 2019 erforscht, wie Nutzer:innen besser über mögliche Risiken aufgeklärt werden können, die sie eingehen, wenn sie online einfach das Häkchen setzen.
Das Problem, das alle kennen: Datenschutzerklärungen sind zu lang und zu schwer zu verstehen. Es würde im Durchschnitt ca. 200 Stunden dauern, die Datenschutzinformationen zu lesen, die uns auf Webseiten oder Apps alltäglich begegnen. Dazu stecken sie voller juristischer und technischer Details, mit denen Laien oft nichts anfangen können – so weit, so offensichtlich.
Hinzu kommt, dass Nutzer:innen, wie Studien zeigen, weniger an die langfristigen Risiken denken, sondern in erster Linie die kurzfristigen Vorteile der digitalen Dienste im Blick haben. „Schließlich denkt niemand an Identitätsdiebstahl oder finanziellen Ruin, wenn er oder sie sich eine App installiert. Bevor Abtreibungen in Teilen der USA illegal wurden, hatte auch niemand daran gedacht, dass die Bewegungsdaten von Frauen, die eine Abtreibungsklinik besuchen, einmal strafrechtlich relevant sein würden. Von den Daten aus der Perioden-App ganz zu schweigen“ so Lukas Seiling, Forscher im Privacy-Icons-Projekt.
Ohne die Hilfe verständlicher Datenschutzinformationen sind Nutzer:innen also nicht in der Lage, eine ausgewogene Risikoabschätzung durchzuführenn und eine informierte Entscheidung zu treffen. Genau das sieht aber die EU-Datenschutzverordnung vor.
Icons, die nicht so viel aussagen
Eine gängige Herangehensweise, um Datenschutzerklärungen besser verständlich zu machen, ist das Einsetzen von Symbolen oder Icons, die auf bestimmte Datentypen oder Verarbeitungszwecke hinweisen. Sie wurden schon von anderen Forschungsprojekten, Vereinen, sowie den Tech-Giganten Google und Apple getestet und umgesetzt. Diese dienen aber im besten Fall als schönere Zwischenüberschriften in den immer noch elendig langen Privacy Policies. Sie liefern keinerlei Information über die Risiken, die wir mit einer Datenverarbeitung eingehen.
Ziel der Forscher:innen war es deshalb, Icons zu entwickeln, die solche risiko-relevante Informationen schnell für Nutzer:innen erkennbar machen. Doch dafür war einiges an Vorarbeit nötig: Die Forschenden unterzogen zunächst einmal die DSGVO einer Inhaltsanalyse, um relevante Konzepte (wie Zweck und Art der Verarbeitung, oder Datentypen) zu identifizieren. Diese diskutierten sie dann mit Expert:innen für Technik, Recht und Psychologie und führten Studien mit deutschen Internet-Nutzer:innen durch.
Riskomodelle – mehr Kontext, bitte!
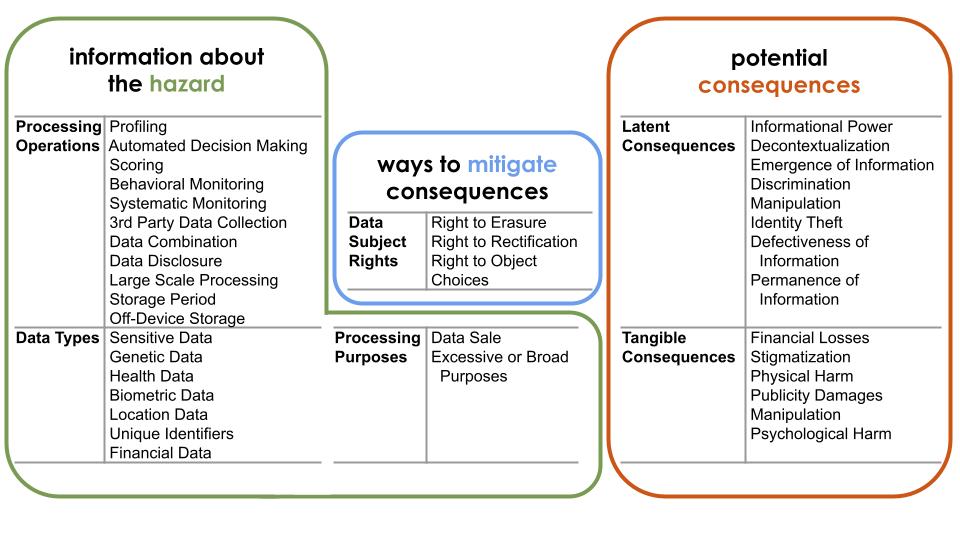
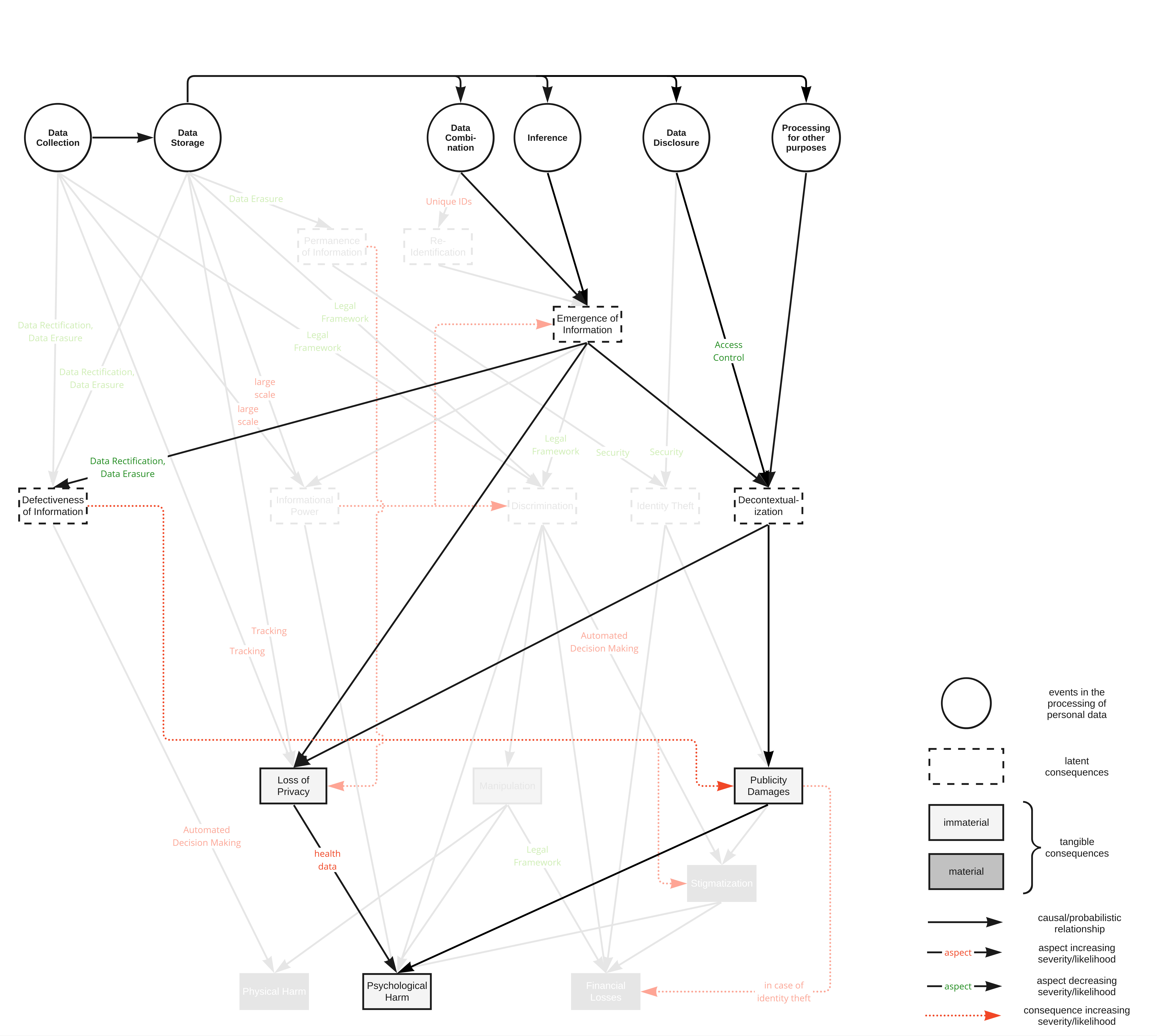
Eine Herausforderung, die bei der Risikokommunikation im Umgang mit persönlichen Daten deutlich wurde: Nutzer:innen bemerken die Konsequenzen von Datenmissbrauch – wenn überhaupt – erst sehr spät. Latente Konsequenzen wie Datendiebstahl oder Datenverlust werden erst spürbar, wenn sie zum Beispiel zu psychischer Belastung oder finanziellen Schäden führen. Das muss gar nicht immer der Fall sein, aber wenn Konsequenzen spürbar werden, dann weil zuvor bereits andere, unsichtbare Konsequenzen, eingetreten sind. Die Forscher:innen haben deshalb ein Modell entwickelt, das die potenziellen Gefahren bei der Datenverarbeitung aufzeigt – sowohl die latenten, als auch die spürbaren. Ebenso geht das Modell auf die Kontexte ein, in denen die Gefahren auftreten könnten. Dabei sind verschiedene Arten von Datenverarbeitung die Ursache latenter Gefahren, die wiederum mit daraus resultierenden spürbaren Konsequenzen verknüpft werden. So werden Risiken für Nutzer:innen konkret und besser einschätzbar.
Ein Beispiel: Anfang 2023 veröffentlichte die Meinungsbloggerin Jasmin Gnu auf YouTube ein Video, indem sie anprangerte, wie sie und andere Content-Creatorinnen massiv sexualisiert wurden. Nutzer hatten Screenshots von Streams sowie Social-Media-Bilder der Influencerinnen für pornografische Zwecke missbraucht und damit unter anderem Deep-Fake-Pornografie erstellt. Dabei werden die Gesichter der Betroffenen mithilfe von Bildgeneratoren in bestehende Pornos eingefügt. Das hat meist schwere psychische Folgen für die Betroffenen und kann auch zu Rufschädigung führen.
Das Modell der Wissenschaftler:innen zeigt, wie sich diese negativen Konsequenzen für die Creatorinnen manifestieren: Voraussetzung ist, dass die Daten der Betroffenen gesammelt und gespeichert werden, in diesem Fall auf Social-Media-Plattformen. Auf dieser Grundlage werden ihre Daten von anderen Nutzern mithilfe von Bildgeneratoren verarbeitet und mit bestehenden Pornos kombiniert. Hiermit entstehen also neue Daten als erste Konsequenz, die allerdings noch nicht direkt auf die Frauen wirkt. Dazu kommt, dass die Deep-Fake-Videos auch noch falsch, bzw. fake sind. Schlussendlich werden die Bilder und Videos durch das Veröffentlichen und Teilen in Online-Foren, wie z.B. sexualisierten Subreddits, aus ihrem ursprünglichen Kontext gerissen – und damit für Zwecke verarbeitet, für die sie ursprünglich nicht gedacht waren. Das ist dann die letzte Konsequenz, die nun spürbar wird: die Betroffen erleiden massiven Rufschaden, das Gefühl, in ihrer Privatsphäre verletzt worden zu sein, was eine starke psychische Belastung bedeutet.
Der wissenschaftliche Artikel, der das Modell vorstellt, wurde kürzlich in einem Journal des Institute of Electrical and Electronics Engineers veröffentlicht. „Wir müssen Nutzer:innen ehrlich kommunizieren, auf was sie sich einlassen, ihnen Möglichkeiten aufzeigen, ihre Daten zu schützen und sie in die Lage versetzen, Risiken in der digitalen Welt besser abzuschätzen“ sagt Rita Gsenger, Forscherin in der Forschungs-Gruppe „Normsetzung und Entscheidungsverfahren“ und Co-Autorin des Papers.
Ein besseres Risikobewusstsein löst zwar keine strukturellen Probleme, wie den Mangel an datensparsamen Alternativen oder sogenannte Dark Patterns, die Nutzer:innen dazu verleiten, auf bestimmte Einstellungen zu klicken. Doch die Modelle können auch bei der Entwicklung besserer Datenschutzmechanismen von Online-Diensten helfen oder Datenschutzbehörden in ihrer Arbeit unterstützen. Zentral bleibt jedoch die Aufklärung der Nutzer:innen über mögliche Risiken. Als Nächstes werden die Wissenschaftler:innen versuchen, sich die in großen Sprachmodellen gespeicherten Sprachzusammehänge zunutze zu machen, um automatisch mögliche Risikoursachen in Datenschutzerklärungen zu erkennen. Sobald dies verlässlich funktioniert, soll auch an einer Visualisierung – sprich den Icons - gearbeitet werden.

