Privacy Icons
Datenschutzrichtlinien sind für viele Menschen schwer zu verstehen. Dieses Projekt zielte darauf ab, Symbole zur Vereinfachung dieser Richtlinien zu entwickeln.
Hintergrund
Bei der Nutzung unterschiedlicher digitaler Dienstleistungen fällt eine Vielzahl personenbezogener Daten an. Laut Datenschutzgrundverordnung (DSGVO) muss über die Verarbeitung dieser Daten in „präziser, transparenter, verständlicher und leicht zugänglicher Form“ (Art. 12(1)) informiert werden. Dies geschieht meist in Form von Datenschutzerklärungen. Allerdings sind diese alles andere als verständlich.
Ziel
Das Privacy-Icons-Projekt hat sich, auf Basis von DSGVO Art. 12(7), das Ziel gesetzt, risikobasierte Icons zu entwickeln, um „einen aussagekräftigen Überblick über die beabsichtigte Verarbeitung zu vermitteln“.
Um effektive Icons zu entwickeln, muss allerdings zuerst geklärt werden, welche Konzepte vermittelt und entsprechend visualisiert werden müssen. Hierbei unterscheidet sich der risikobasierte Ansatz von anderen Icon-Projekten, da er das Eintreten möglicher negativer Auswirkungen von Datenverarbeitung (Risiken) in den Vordergrund stellt und sich somit effektiv mit der Konzeption von Warnungen beschäftigt.
Für die effektive Entwicklung von Warnungen stellten sich dabei folgende primäre Forschungsfragen:
- Was sind relevante Informationskategorien für Risikokommunikation im Kontext der Verarbeitung personenbezogener Daten?
- Welche möglicherweise negativen Konsequenzen können sich auf welche Weise aus der Verarbeitung personenbezogener Daten ergeben?
- Wie können diese negativen Konsequenzen abgemildert oder vermieden werden?
Weiterführende Forschungsfragen betrafen die spezifische Visualisierung der korrespondierenden Informationskategorien sowie die Gestaltung eines effektiven Warnungssystems.
Methoden
Um die oben genannten Forschungsfragen angemessen zu beantworten, war der Einsatz unterschiedlicher Methoden notwendig:
Literatur-Review & Modellentwicklung zur Schaffung einer theoretischen Grundlage, um den kontextabhängigen Entstehungsprozess negativer Konsequenzen bei der Verarbeitung personenbezogener Daten zu verstehen und zu Zwecken weiterer Analyse zu formalisieren.
Systematische Qualitative Inhaltsanalyse von DSGVO und Expert:inneninterviews, um relevante Informationskategorien und zu identifizieren.
Delphi-Studie zur Sortierung und Gewichtung der Unterschiedlichen Informationskategorien.
Quantitative Analyse von Codehäufigkeiten (aus der Inhaltlsanalyse) sowie in Delphi-Studie gesammelten Einschätzungen
Ergebnisse
In der vorläufigen Projektabschlusspublikation werden mehrere Ergebnisse präsentiert:
1. Kontextuelles Modell wahrgenommener Privatheitsrisiken, dass das Konzept wahrgenommener Risiken um Helen Nissenbaum’s Theorie kontextueller Integrität erweitert.

2. Überblick über mögliche Ursachen und negative Konsequenzen in der Verarbeitung personenbezogener Daten, wobei in Latente („latent“, gestrichelte Linie) und Konkrete („tangible“, grau schattiert) Konsequenzen unterschieden werden muss ( > Während konkrete Konsequenzen klar kontextuell verankert und erlebbar sind, sind latente Konsequenzen oft nicht unmittelbar bekannt oder ereignen sich, ohne dass die Betroffenen sich darüber bewusst sind).

3. Übersicht relevanter Informationskategorien für die Kommunikation von Privatheitsrisiken:
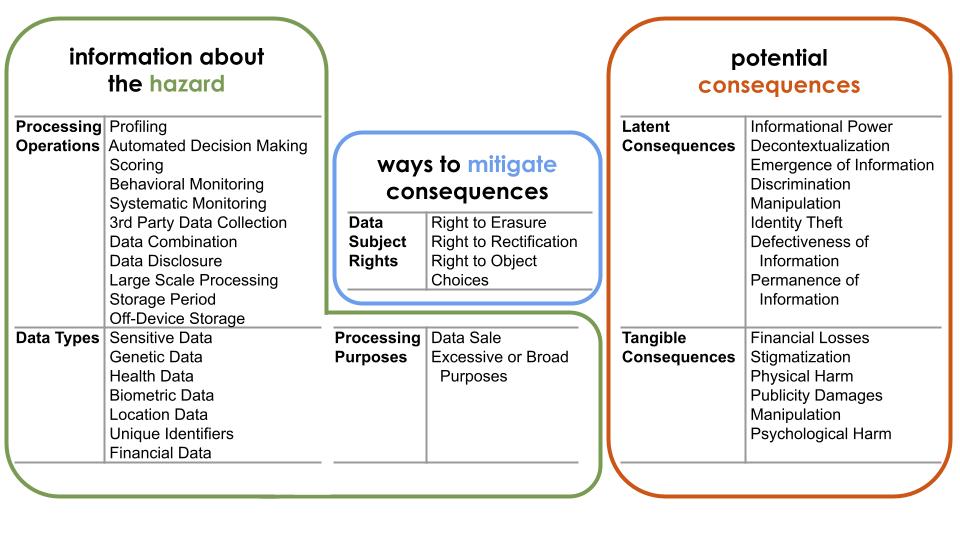
Ausblick
Die Ergebnisse des Projekts sollen in Zukunft für die Entwicklung eines Warnsystems verwendet werden, das relevante Informationen visuell darstellt, ohne die Nutzer zu überfordern. Es wird sich auf die automatische Analyse von Datenschutzrichtlinien stützen und die entwickelten Kategorien nutzen, um ein Sprachmodell (LLM) für die automatische und skalierbare Analyse von Datenschutzrichtlinien zu trainieren.

